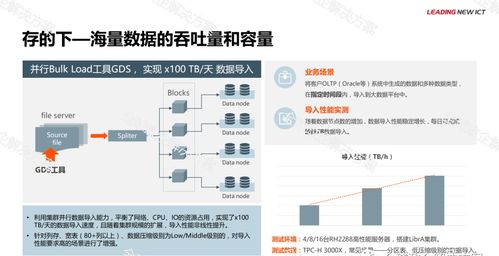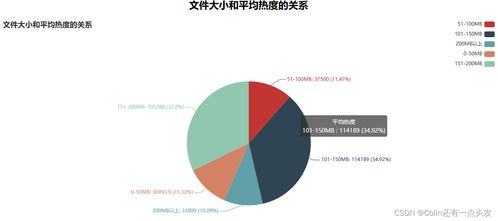
引言
在当今数字化音乐时代,用户面临着海量的音乐选择,如何为用户提供个性化的音乐推荐成为音乐平台的核心竞争力。基于Hadoop的音乐推荐系统通过分布式计算能力,能够有效处理大规模用户行为数据,实现精准推荐。其中,数据处理服务作为整个系统的基石,承担着数据采集、清洗、转换和存储的关键任务。
系统架构概述
数据处理服务在整个推荐系统中处于基础层,主要负责:
- 用户行为数据采集(播放记录、收藏、评分等)
- 音乐元数据管理(歌曲信息、歌手、专辑等)
- 数据预处理和特征工程
- 数据存储和管理
数据处理流程设计
1. 数据采集模块
数据采集模块负责从各个数据源收集原始数据:
- 用户行为日志:通过日志收集系统(如Flume)实时采集用户交互数据
- 音乐元数据:从音乐数据库定期同步更新
- 第三方数据:通过API接口获取社交网络数据、音乐标签等
2. 数据清洗与预处理
基于Hadoop MapReduce的数据清洗流程:
- 数据去重:消除重复的用户行为记录
- 异常值处理:识别并处理异常播放时长、异常评分等
- 缺失值填充:采用均值填充或基于协同过滤的预测填充
- 数据格式化:统一时间戳格式、编码格式等
3. 特征工程
特征提取是推荐质量的关键:
- 用户特征:用户画像、收听偏好、活跃时段等
- 物品特征:音乐类型、节奏、情感标签、流行度等
- 上下文特征:时间、地点、设备类型等
- 交互特征:播放频次、完整播放率、重复收听率等
Hadoop技术栈实现
1. 数据存储方案
- HDFS:存储原始日志和预处理中间数据
- HBase:存储用户画像和音乐特征数据,支持快速查询
- Hive:构建数据仓库,支持复杂的分析查询
2. 数据处理框架
- MapReduce:用于批量数据处理和特征计算
- Spark:用于实时特征更新和流式处理
- Sqoop:实现关系型数据库与Hadoop集群的数据同步
3. 数据质量监控
- 建立数据质量指标体系
- 实现数据血缘追踪
- 设置数据异常告警机制
核心算法实现
1. 用户行为权重计算
用户偏好得分 = α × 播放次数 + β × 收藏权重 + γ × 评分权重 + δ × 分享权重2. 音乐相似度计算
基于内容相似度和协同过滤相似度的综合计算:`
综合相似度 = ω₁ × 内容相似度 + ω₂ × 协同过滤相似度`
3. 特征标准化
采用Min-Max标准化和Z-score标准化相结合的方法,确保不同量纲特征的公平比较。
性能优化策略
1. 数据分区优化
- 按时间分区处理历史数据
- 按用户ID哈希分区提高并行度
- 热点数据单独处理
2. 计算优化
- 使用Combiner减少MapReduce数据传输
- 数据本地化优化
- 内存调优和垃圾回收优化
3. 存储优化
- 数据压缩(使用Snappy、LZO等压缩算法)
- 列式存储优化查询性能
- 数据生命周期管理
系统监控与维护
1. 监控指标
- 数据处理吞吐量
- 任务执行成功率
- 数据质量指标
- 集群资源利用率
2. 故障处理
- 实现数据备份和恢复机制
- 设置任务重试和容错机制
- 建立数据一致性校验流程
应用效果与展望
通过基于Hadoop的数据处理服务实现,系统能够:
- 日处理TB级用户行为数据
- 支持毫秒级特征查询
- 实现99.9%的数据处理成功率
- 显著提升推荐准确率和用户满意度
我们将进一步探索:
- 引入深度学习模型进行特征学习
- 实现更细粒度的实时数据处理
- 优化多源数据融合技术
- 提升系统的自适应学习能力
结语
数据处理服务是基于Hadoop的音乐推荐系统的核心组件,其设计质量和实现效果直接决定了整个推荐系统的性能。通过合理的架构设计、高效的算法实现和持续的优化改进,我们能够为用户提供更加精准、个性化的音乐推荐体验,推动音乐平台的持续发展。